Speechly Streaming API
With the Speechly Streaming API you can transcribe speech in real-time with intent and entity detection. Ideal for creating reactive voice user experiences.
This document describes the low-level gRPC API. For most users we recommend using the API via one of our Client Libraries that are available for popular platforms.
Overview
The Speechly API consists of three services: the SLU provides spoken language understanding, the WLU written language understanding, and the Identity provides authentication and identity service.
The difference between SLU and WLU is that the former is used for audio data, whereas the latter works with text. The SLU provides speech recognition (ASR) and natural language understanding (NLU) by extracting intents and entities from the voice data. The WLU works with the same model but only provides natural language understanding.
Initializing Speechly API
A new stream is started by initializing the SLU engine with a config value. Configuration requires a token that can be obtained through the Identity service. Authentication requires a unique device ID and a Speechly application ID.
Once the Identity service is provided with a valid application ID and device ID, it returns a token that must be sent along with the SLUEvent.START request.
Last part of initializing the Speechly SLU API is configuring the audio input. This configuration is sent as a SLUConfig message containing the sample rate, the number of channels, the encoding of the audio data, and the language used.
The user voice input can be of any length, but it must be divided into chunks of less than one megabyte. The minimum sample rate is 8000Hz (16000Hz recommended), the minimum number of channels is one, and the only supported encoding so far is signed PCM.
A sample of a valid audio file can be downloaded here.
When the configuration is done, the stream moves into the “SLU event loop” state.
SLU event loop
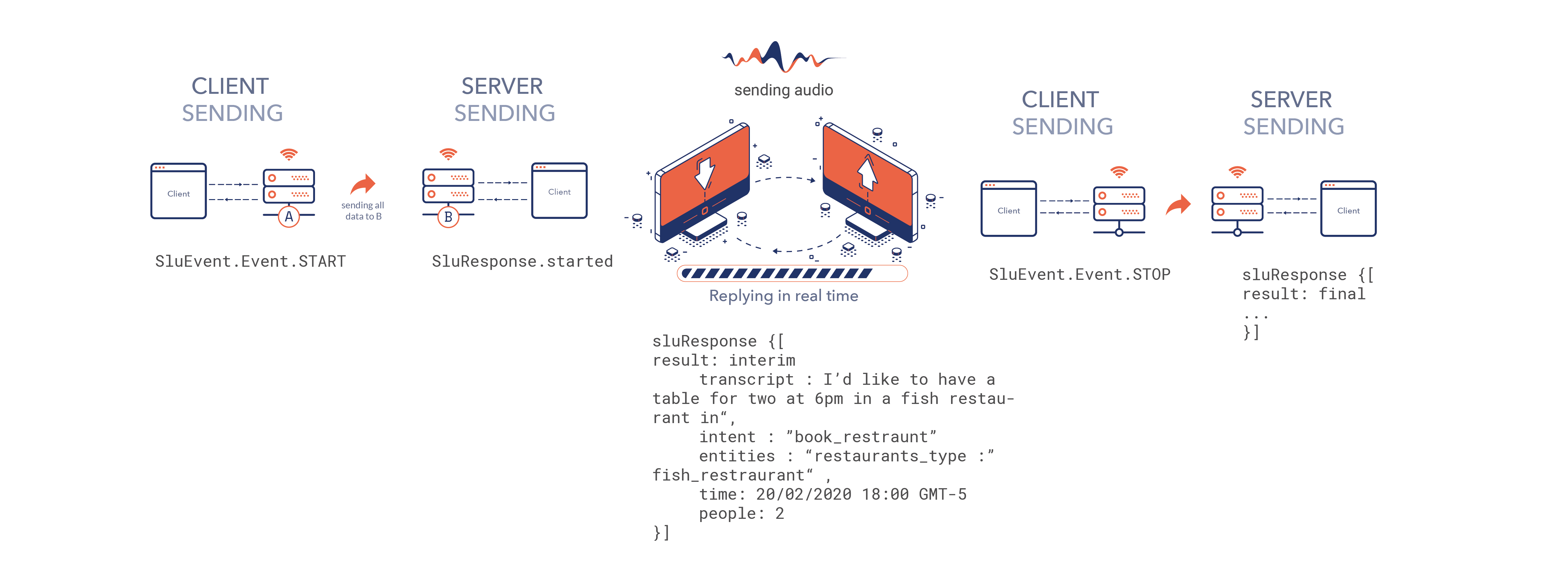
The process of the SLU event loop is the following:
- The client sends the
SLUEvent.Event.STARTevent when a user wants to start speaking. - The server sends the
SLUResponse.startedwhen it’s ready to receive audio. It also sends theaudio_contextUUID to the client. - The client sends the configuration.
- The client sends audio chunks, which need to be under one megabyte.
- The server sends the
SLUResponsefor the events, and the utterance results. For each segment in the utterance, it sends a rolling ID. - The client sends the
SLUEvent.Event.STOPevent when no more audio is sent for the utterance. - The server processes all the received audio before the stop event, and sends out the segment results. It finishes with the
finished response.
Only one segment can be active at a time, but the old segments can still concurrently send results while a new segment is being processed.
The event SLUEvent.Event.START is sent before stopping the current on-going utterance with SLUEvent.Event.STOP, or else the whole stream is killed with an error. This is to ensure that the clients are well behaved.
For information about server-sent messages, see SLUResponse.
Understanding server responses
Once the client starts sending audio stream, the server sends SLUResponses of two kinds: tentative and final. The tentative results are typically used for prefetching data and for UI purposes. Once the server sends the final results, the tentative ones are discarded, and only the final results are used for the application business logic.
The audio stream sent to the server can consist of one or more segments, and it can be of any length. A segment is typically one sentence, but it can also include several. Correspondingly, a sentence can consist of more than one segment. A segment can contain zero or one intent and any number of entities and their values. The audio stream gets divided into segments either by user silence, or when the server recognizes a new intent.
The audio stream stays open until stopped with the SLUEvent.Event.STOP. If the user pauses and then continues speaking, the utterance is divided into two segments — the first segment gets the final results, and the tentative results begin for the new segment.

Glossary
Entity: Entities are modifiers for intents. For example, in the utterance, “Add milk to my shopping list,” the intent of adding products to a shopping list (*ADD_PRODUCT) has a modifier (i.e., entity) PRODUCT, whose value is “milk”. An intent can have any number of entities and values for these entities.
Intent: Intent is the purpose of the utterance. It is analogous to method in programming. For example, the intent of the utterance “Add milk to my shopping list,” is to add a product to a shopping list. Segments can have zero or one intent.
Segment: A segment is an utterance (or part of an utterance) that includes zero or one intent. One utterance can contain one or more segments. For example, “Turn on the living room light and change the color to red,” is an utterance that consists of two segments for the reason that there are two intents: one about turning the light on, and other for changing the color of the light.
Utterance: An utterance in the Speechly terminology is something the end-user says. The utterance is sent to the Speechly API, which in return, returns the utterance transcript, the intents and entities; and if necessary, divides the utterance into segments.
Last updated by Mathias Lindholm on June 20, 2022 at 16:45 +0300
Found an error on our documentation? Please file an issue or make a pull request